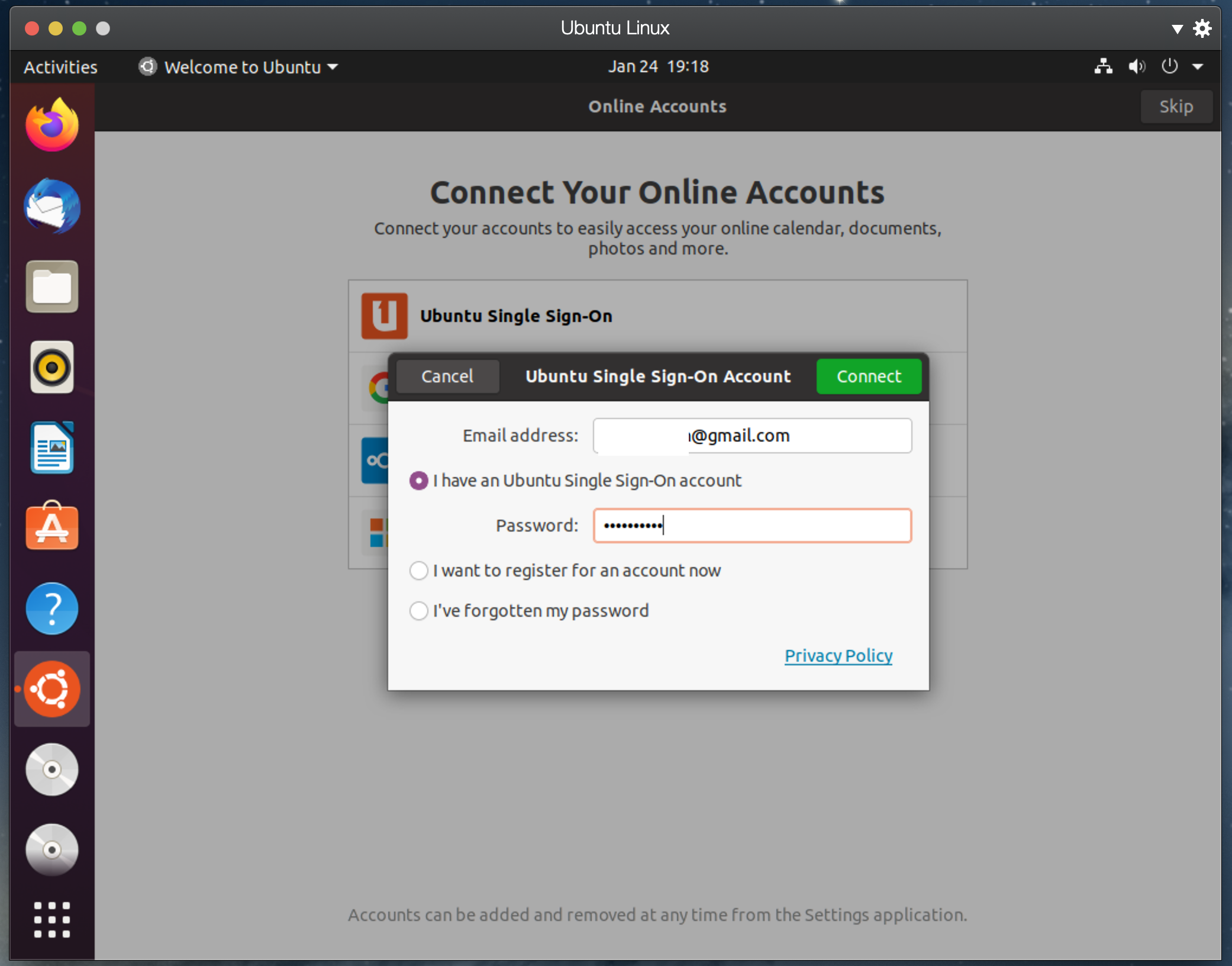
패러렐즈 - 우분투 설치 1 에 이어 간다.
설치하고 나면, 영어로 되어 있다. 한글 패치를 해보자.

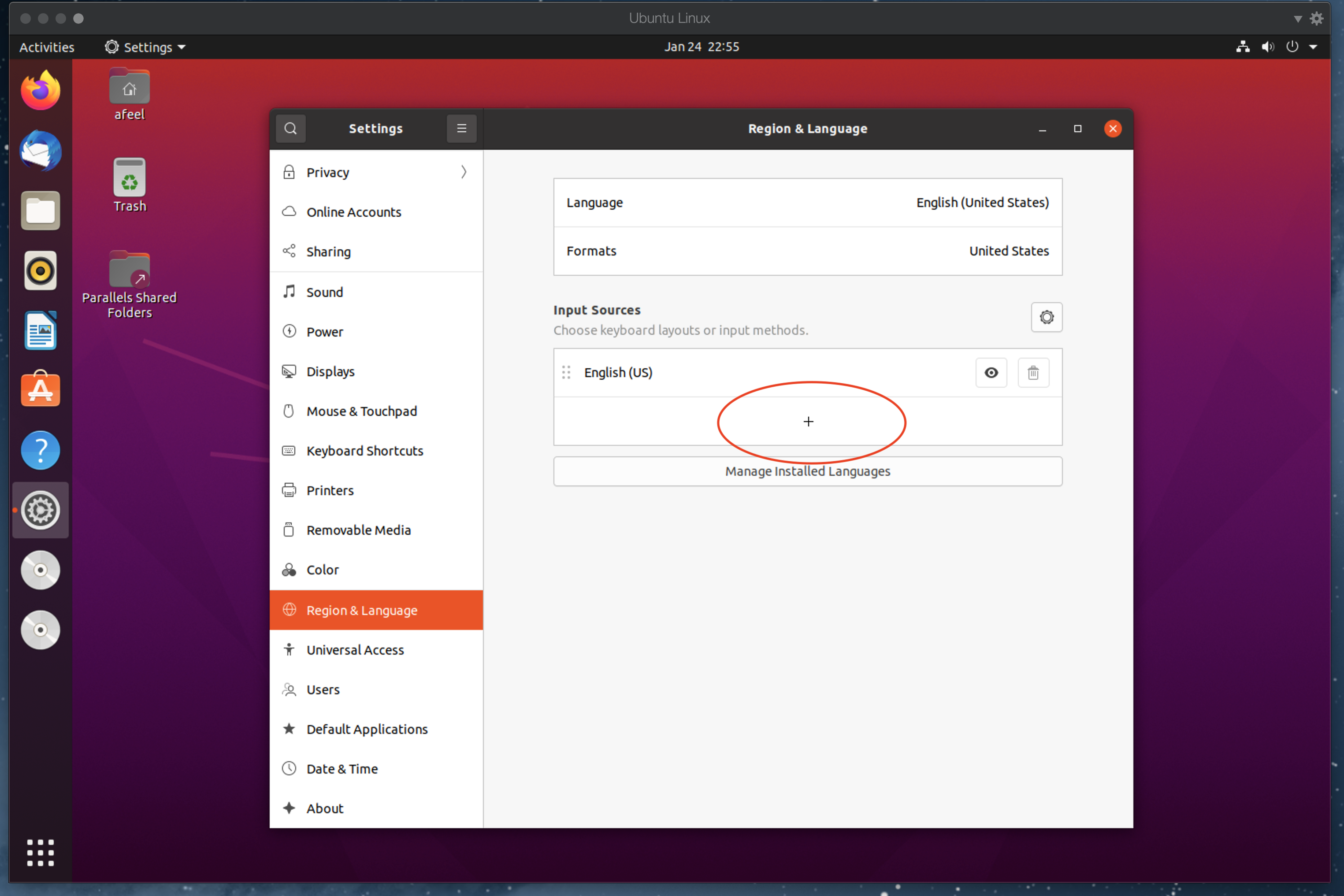
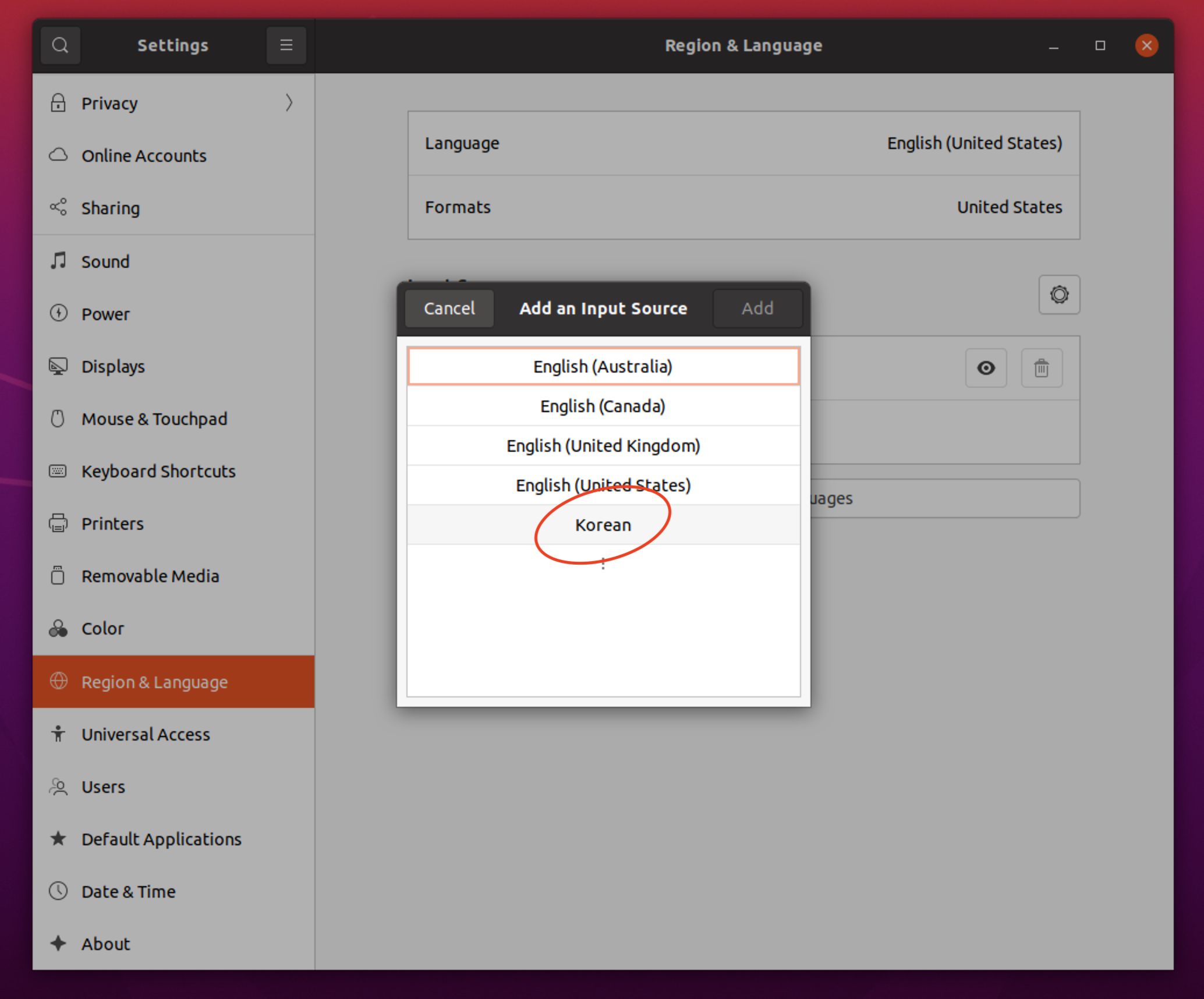
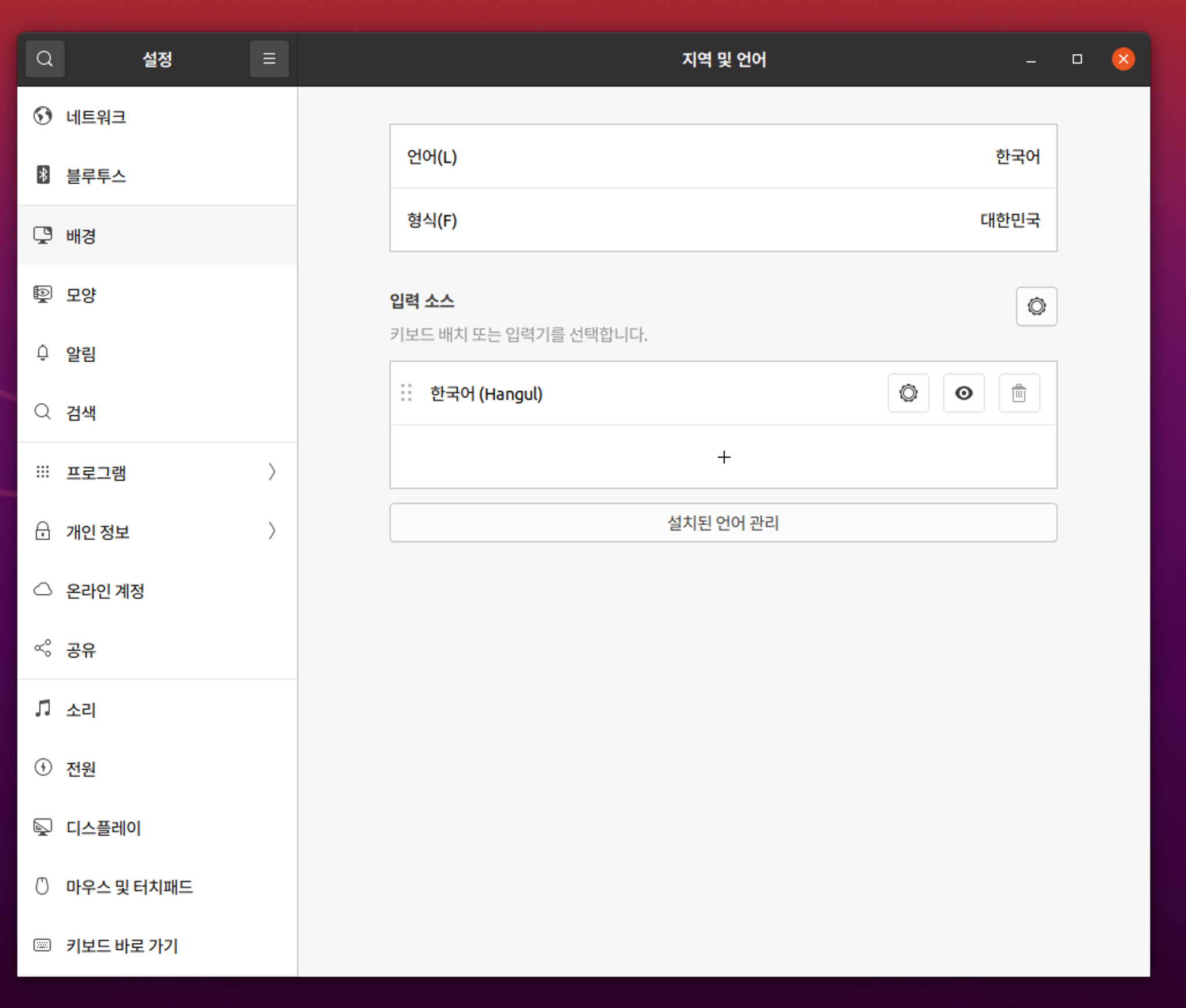
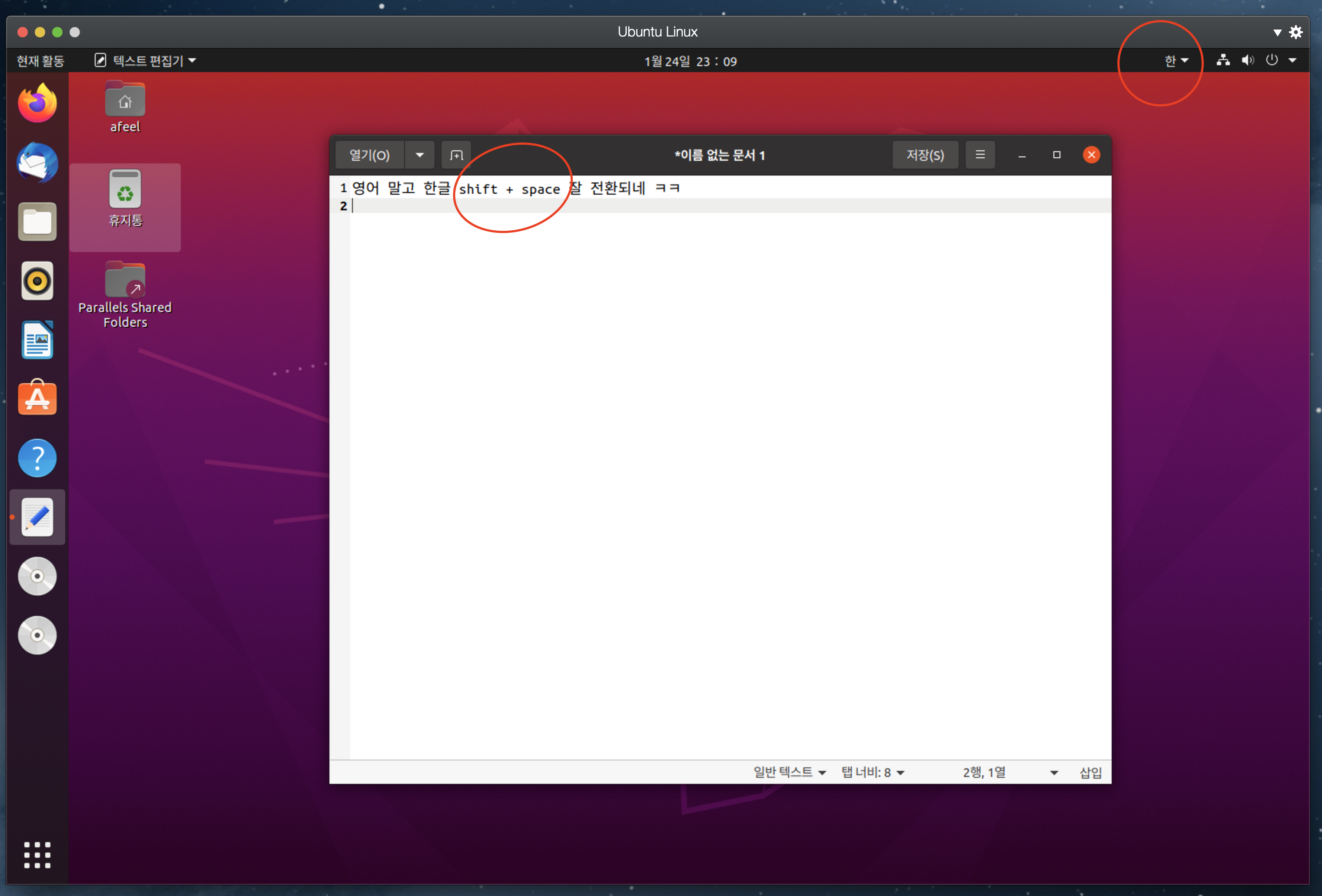
언어를 바꾸면 리부팅을 하는데, 리부팅 후, 기존의 폴더 이름들을 한글로 바꿀건지 물어보면,
바꾸지 말고 영어로 유지하는것이 편하다.
shift + space 를 누르면, 우상단 [한] <->[EN]이 전환된다면, 한글 패치가 끝난다.
패러렐즈 - 우분투 설치 1 에 이어 간다.
설치하고 나면, 영어로 되어 있다. 한글 패치를 해보자.
언어를 바꾸면 리부팅을 하는데, 리부팅 후, 기존의 폴더 이름들을 한글로 바꿀건지 물어보면,
바꾸지 말고 영어로 유지하는것이 편하다.
shift + space 를 누르면, 우상단 [한] <->[EN]이 전환된다면, 한글 패치가 끝난다.
내친김에 리눅스도 설치 해본다.
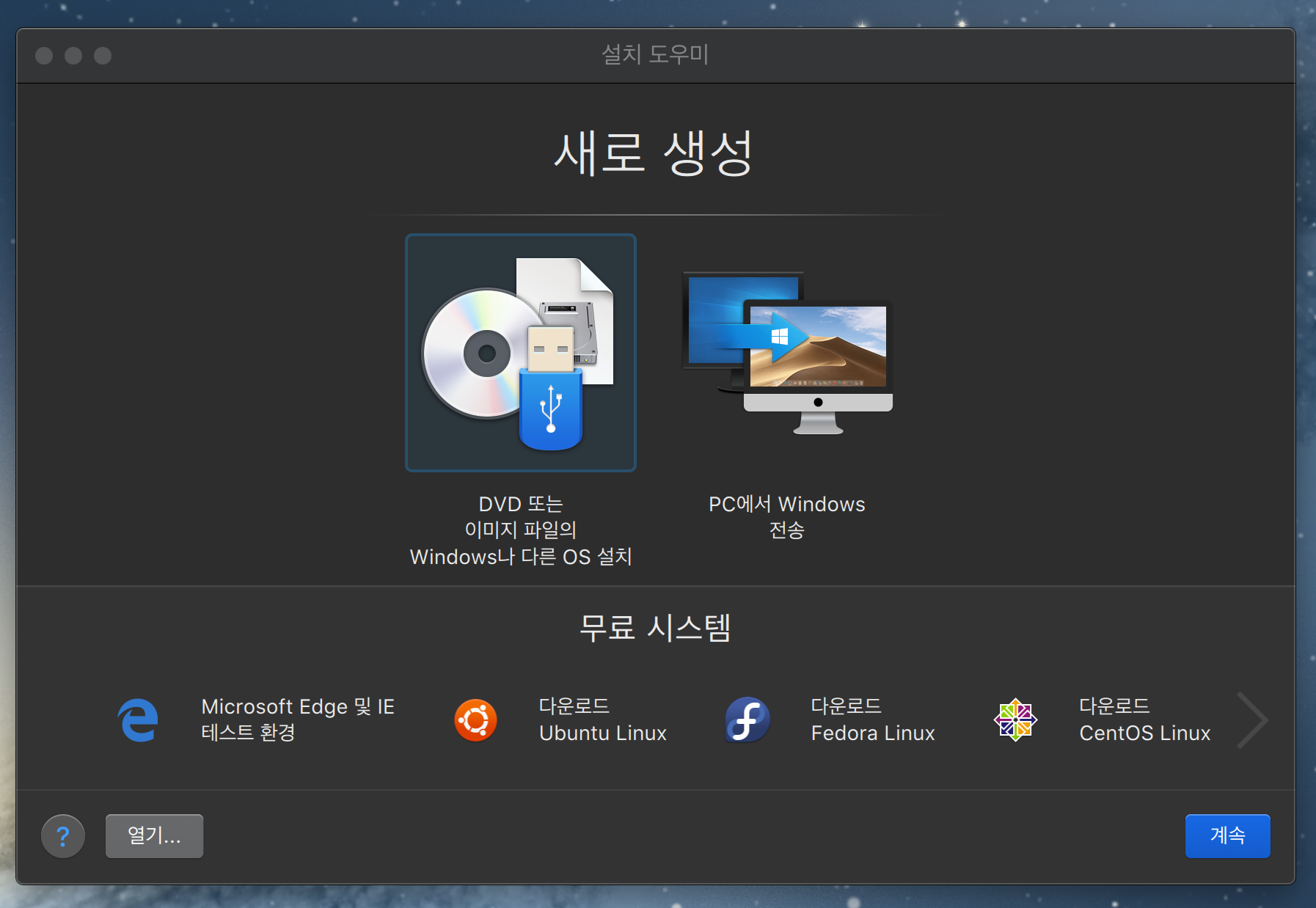
하나의 ISO받는다. 참고로 20.04.1 LTS버전을 받았다. Download Ubunto Desktop
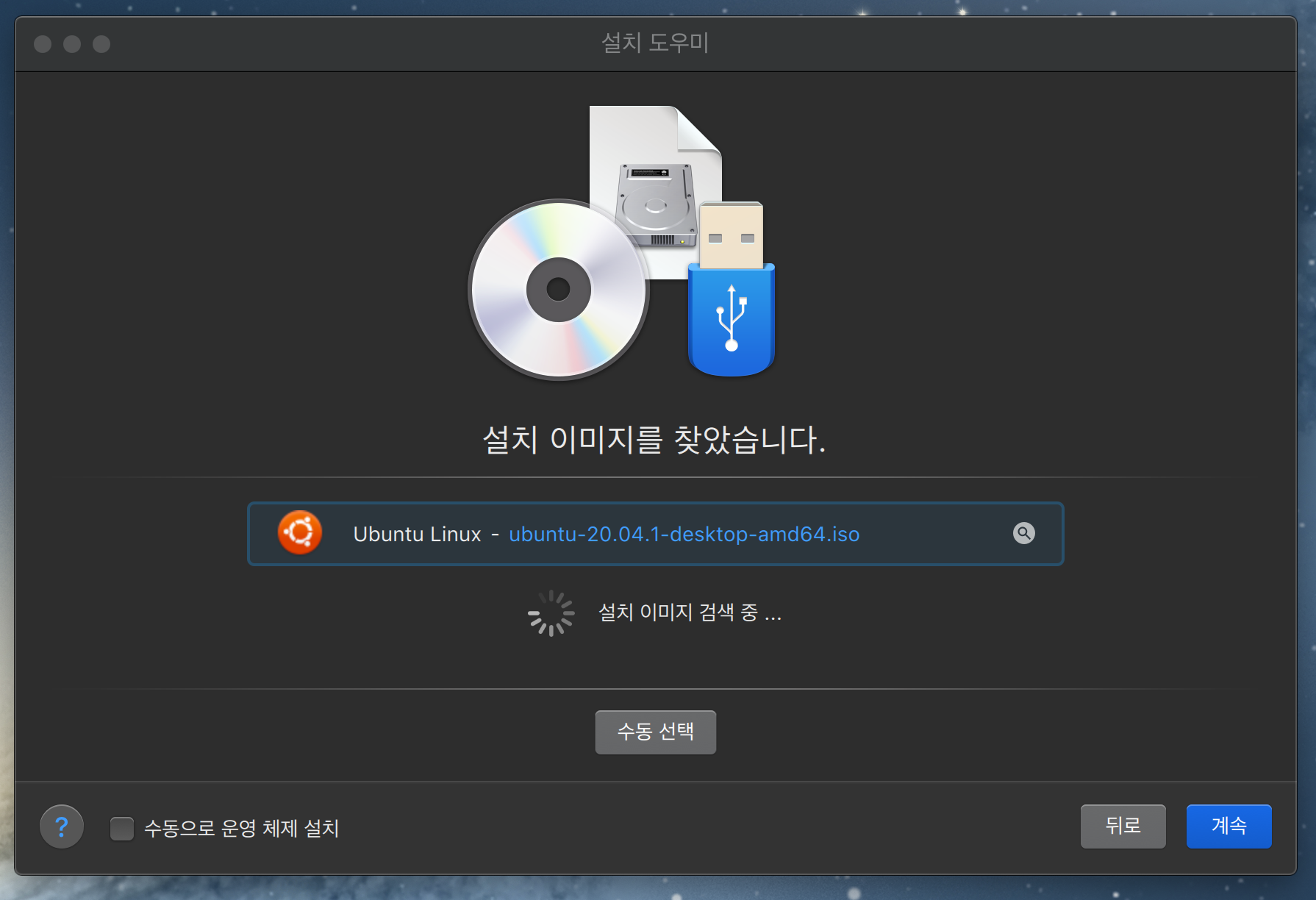
로그인 하고 첫 화면이다.
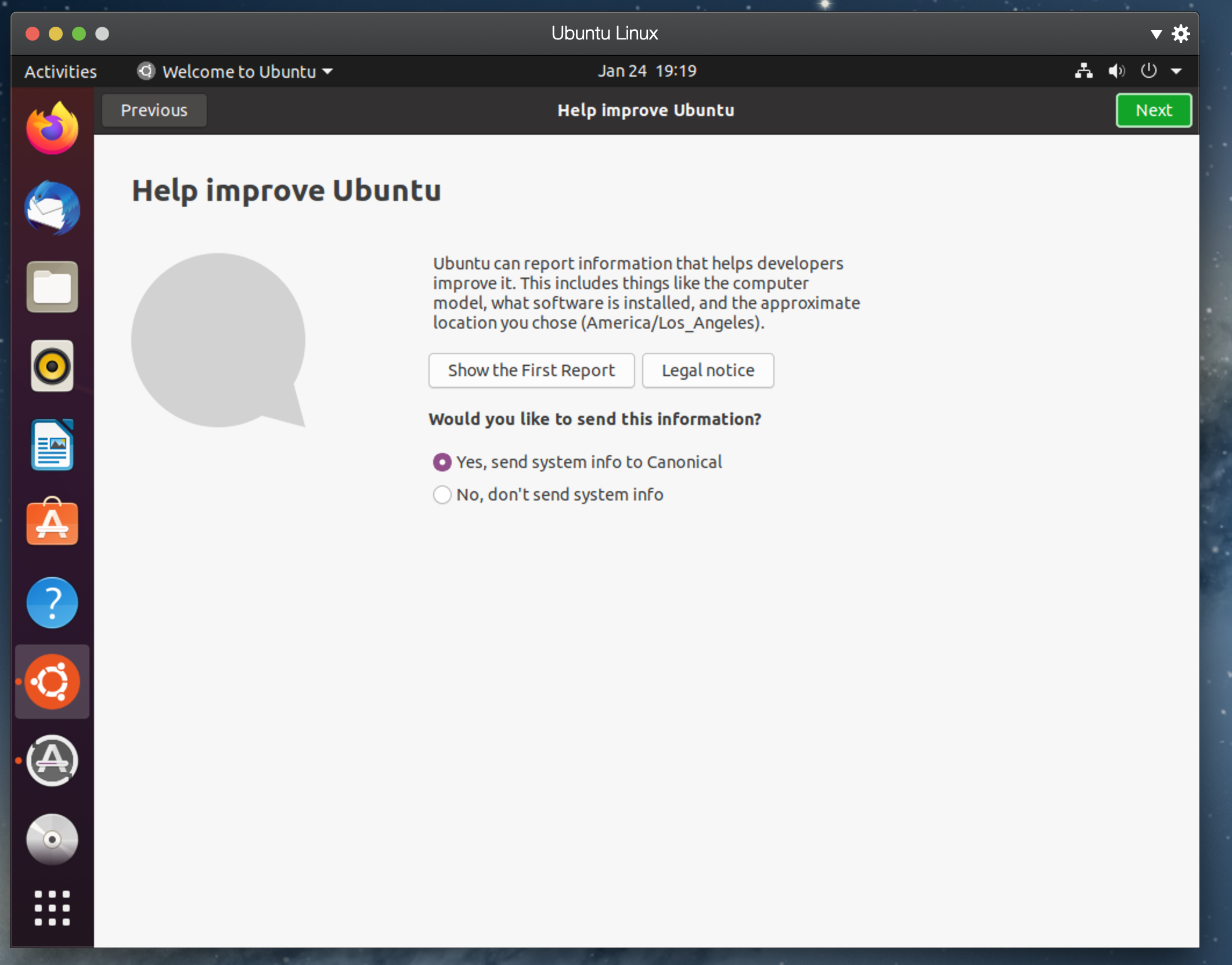
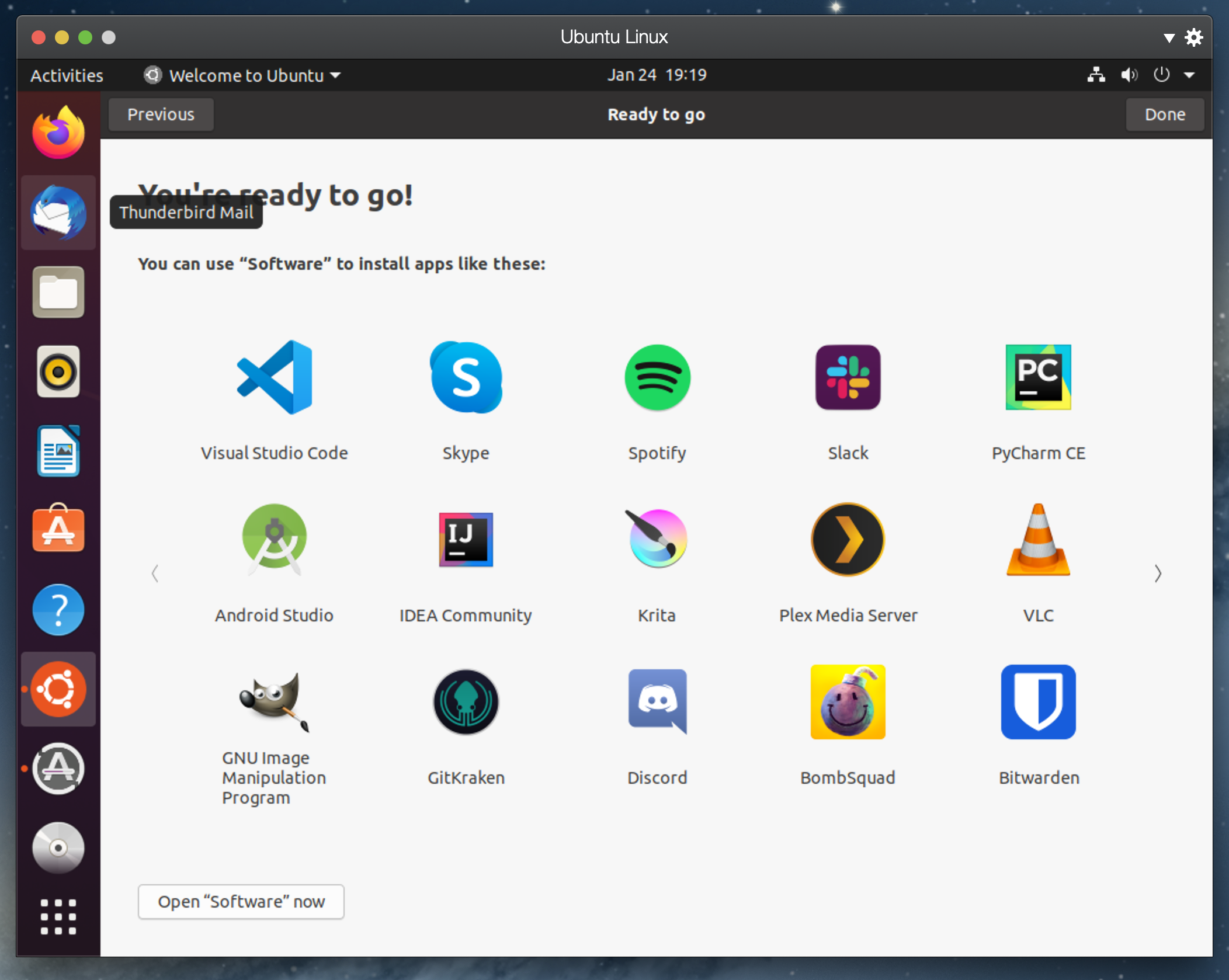
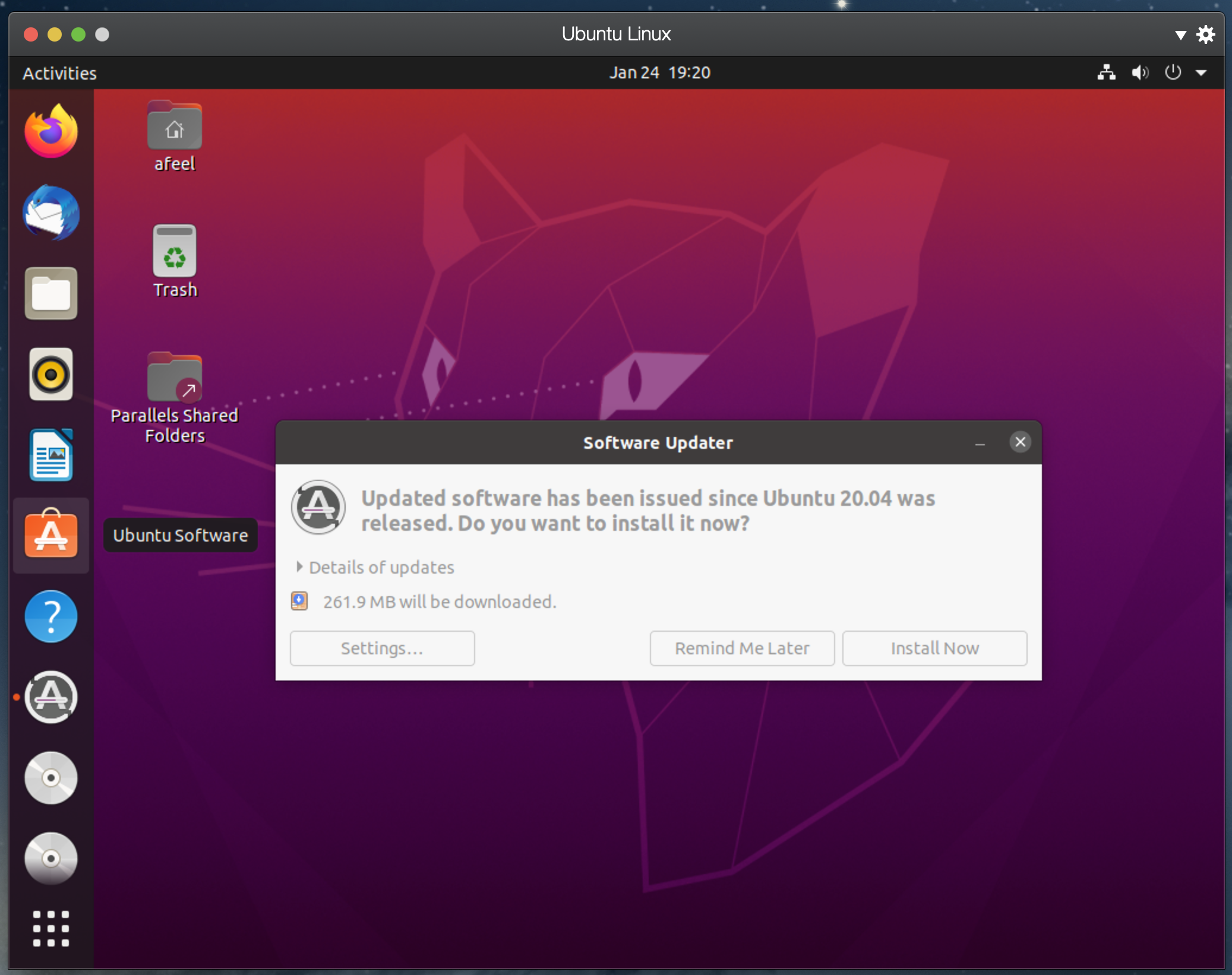
일단 리눅스라는 놈을 설치해봤으니, 좀 더 만지작 거려보자.
패러렐즈 - Mac과 Windows 10 멀티 부팅 에 이어 간다.
이전 글에서는 부트캠프에 설치된 것을 맥에서 구동하는것이라서 수정 작업을 하게 되면 부트캠프 데이터가 수정된다.
당연하지만, 부트캠프로 부팅을 하면 바뀐것을 확인 할 수 있다.
그런데 이번에는 부트캠프를 복제(백업, pvm 확장자) 해보자.
제어센터에서 [마우스 우클릭], [Boot Camp 들여오기]를 클릭 한다. 그 다음 원하는 이름 입력한다.
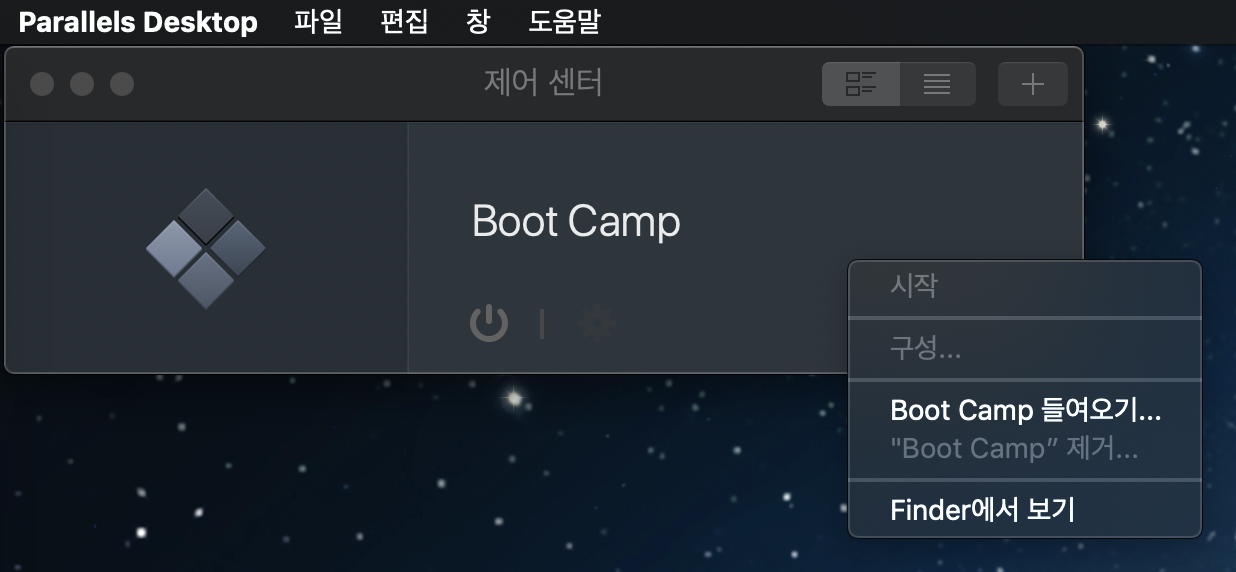
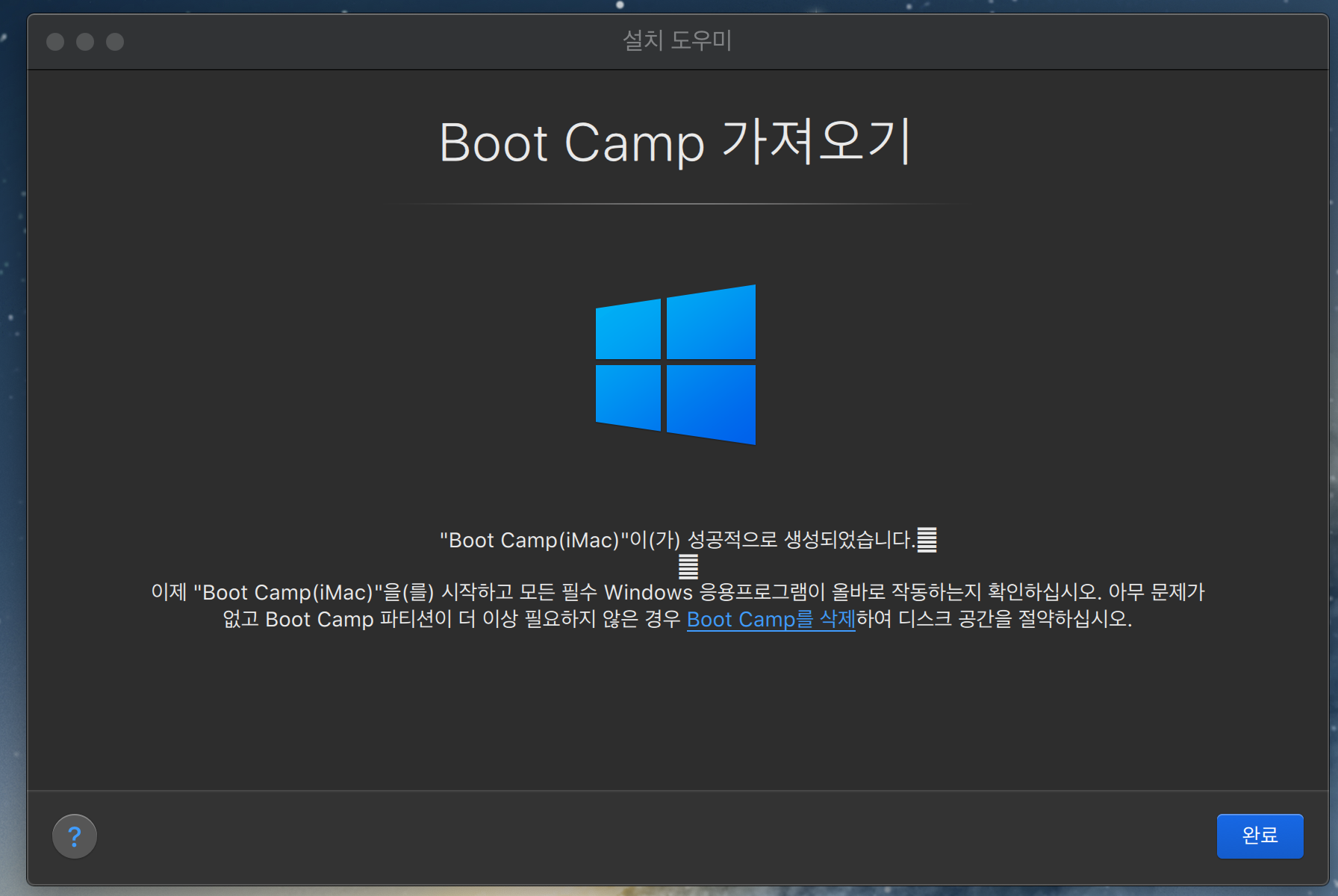
부트캠프가 2개가 보인다. 실행 해보면 기존에 있던 부트캠프와 동일하게 실행된다.
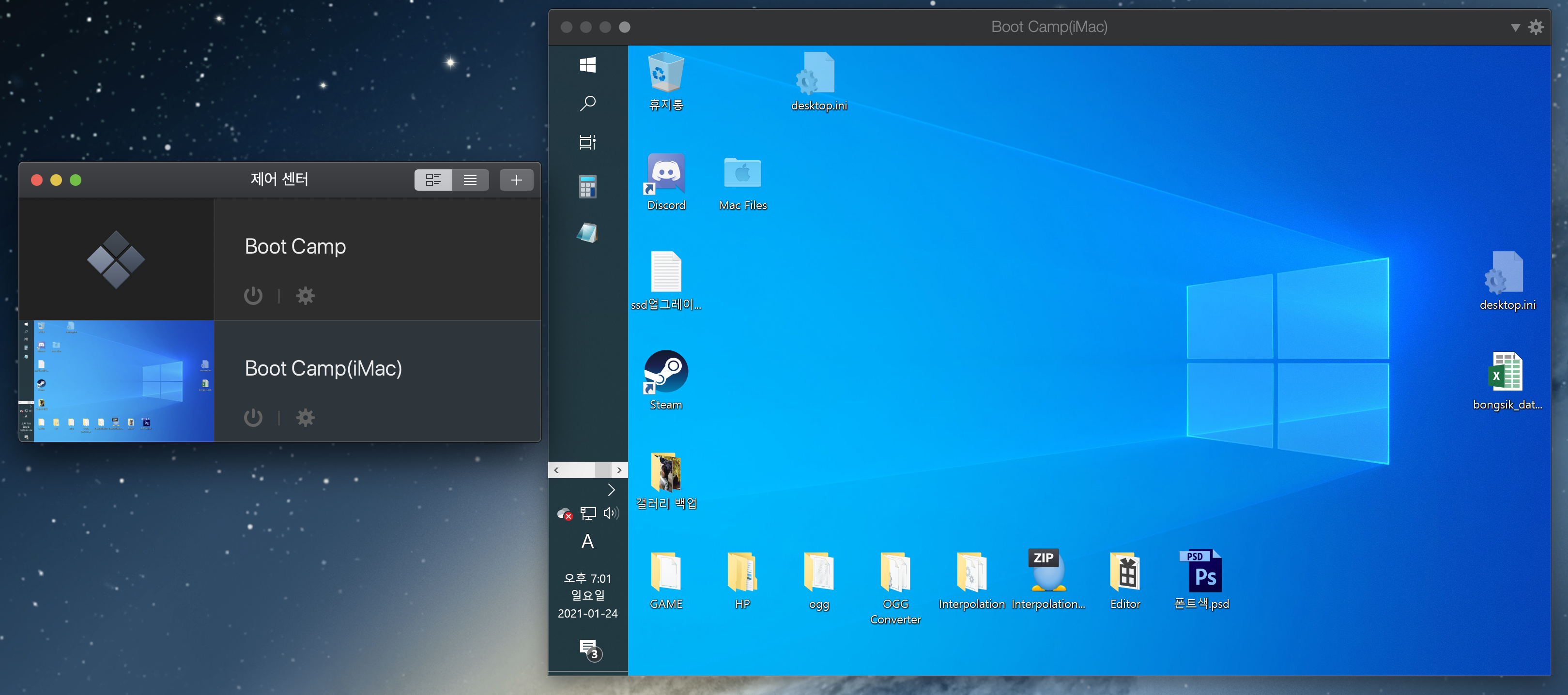
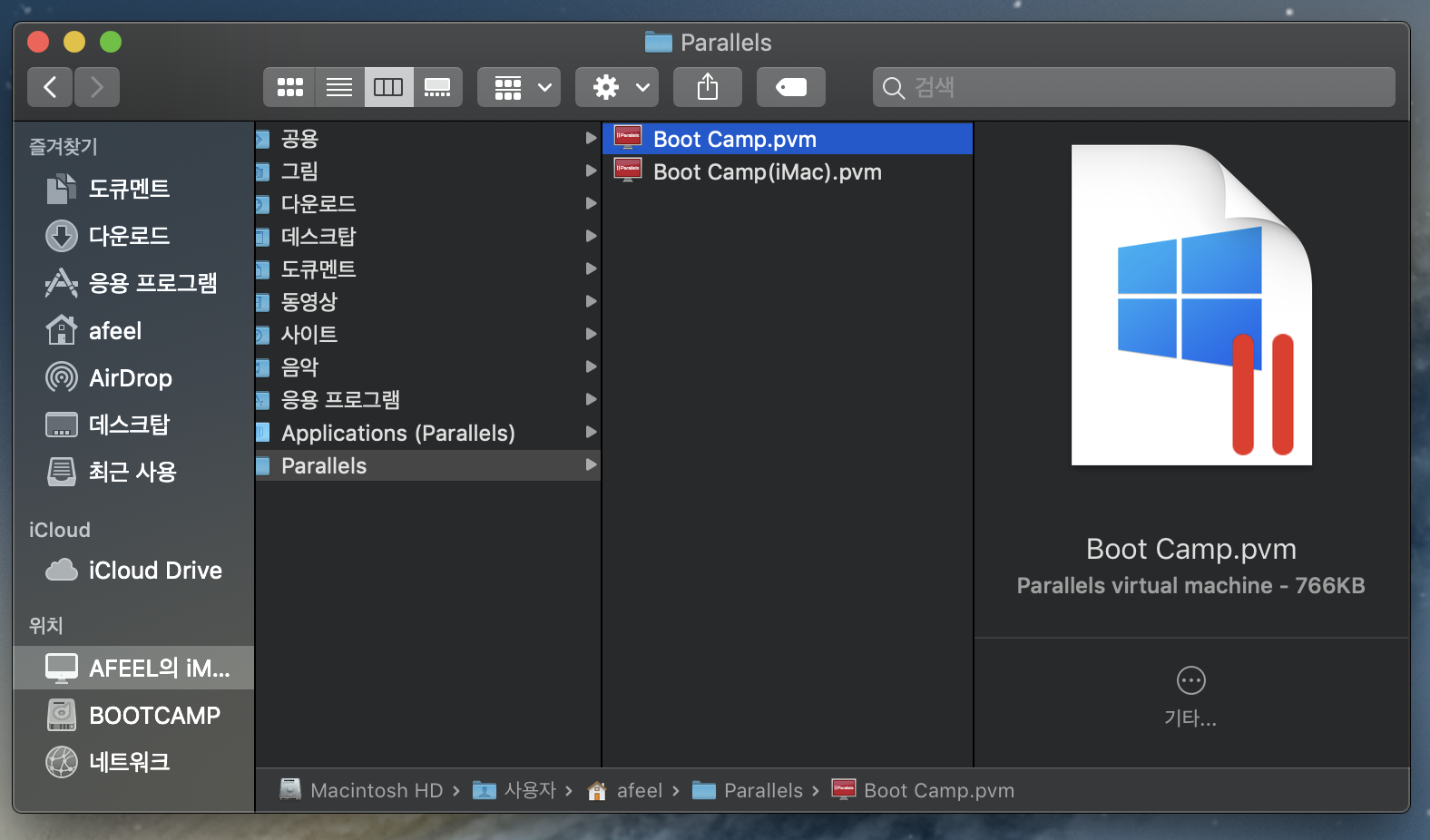
사용자 > (사용자이름) > Parallels 폴더로 가보면, 2개의 파일도 존재함을 알수 있다.
용량을 보면 이전 글에서 만든 Boot Camp.pvm는 766kb 이며, 이번 글에서 만든 Boot Camp(iMac).pvm은 92.26GB 다.
Boot Camp.pvm 실제 부트캠프를 참고해서 쓰는 것, Boot Camp(iMac).pvm은 부트캠프를 복제하여 새로 만든 것이다.
따라서, Boot Camp(iMac).pvm만 있으면 실제 부트캠프 볼륨이 없어지더라도 현재 상태의 부트캠프를 호출할 수 있도록 백업이 된 셈이다.
게다가 이것을 parallels가 설치된 다른 맥에서도 구동이 가능하다.
성능이 딱히 요구하지만 않고, 저장공간을 늘리고 싶다면, 실제 부트캠프를 지우고, Boot Camp(iMac).pvm만 사용해도 된다.
부트 캠프는 3가지 방식으로 구동이 가능해진다.
1. 전원을 넣고 option을 누른 상태에서 부트캠프 부팅.
2. 하나의 OS 위에 네이티브 부트 캠프 구동.(패러렐즈 - Mac과 Windows 10 멀티 부팅 여기서 사용한 방법)
3. 하나의 OS 위에 복제본으로 만든 부트 캠프 구동.(이번 글에 사용한 방법)
속도는 당연히..1 > 2 > 3 일테고, 3이 용량면에서는 가장 유리하고, 백업 기능도 해준다.
쓰는 사람에 따라 필요한것이 다를테니 알아서...
컴퓨터 전원을 켜서, 저장 장치에 설치된 여러 OS들 중 하나를 부팅하는것을
멀티 부팅이라고 칭하는 것은 너무 옛말과 같다.
HDD를 SSD로 대체함으로써, 컴퓨터 심폐소생술을 썼다는 둥...그런 말이 얼마전에 나왔던것 같은데,
요즘은 nvme m.2 삼성 970 evo (plus), pro 성능을 보고 있자면...저절로 입고리가 올라간다.
하드웨어 뿐만 아니라, 소프트웨어도 상상 할수 없을 정도로 눈부시게 발전했고, 따라 가기 버거울정도로 발전하고 있다.
지금 소개할것은 Parallels Desk, Virtual Box, Vmware Fusion 와 같은 가상머신이다.
컴퓨터에 주 OS가 구동되고, 그 위에 가상 머신처럼 하나의 창에 또 다른 OS가 구동가능하게 해주는 소프트웨어다.
하드웨어와 소프트웨어 발전의 결정체인 셈이다.
10여년 전, Virtual Box와 Vmware Fusion을 사용한적이 있는데, 너무 느려서... 도저히... 진짜 10원짜리가 그냥... 나왔다.
최근 사람들이 패러렐즈 많이 좋아졌다길래... 3개의 소프트웨어를 다 설치 해봤다.
소프트웨어를 선택하는데 있어서는 주관적인 부분이 많이 들어간다.
어디까지나 주관적인 부분이니...색안경 안보고 글을 봐주길 바란다.
가상머신 비교한곳이 많다. 그냥 믿으면 된다. 괜히 의심하고 다 설치한다고 시간 낭비만 했다.
그냥 패러렐즈다. 무료 평가판 설치해보면 안다.
설치하는 방법, 사용 방법이 압도적으로 편하고 실행 속도 비교 자체가 의미없다.
최적화가 얼마나 잘 되었는지 발열도 엄청나게 차이 난다. 그냥 비교 자체가 의미가 없다고 봐야 한다.
실제 용량도 패러렐즈가 가장 작았다.(www.parallelskorea.com 이 사이트 가지마라.)
정말 단점이라고는 비용이다. 버추얼 박스는 처음부터...그리고 지금도 여전히 무료!!
vmware fusion는 12가 나오면 처음으로 일반인에게 무료로 배포했다고 한다.
비용이 부담스러우면 이것도 괜찮긴 한데...
각자 알아서 판단하길...
라이센스 키 너무 뚫어지게 보지마라. 회원가입하면 라이센스키 준다.
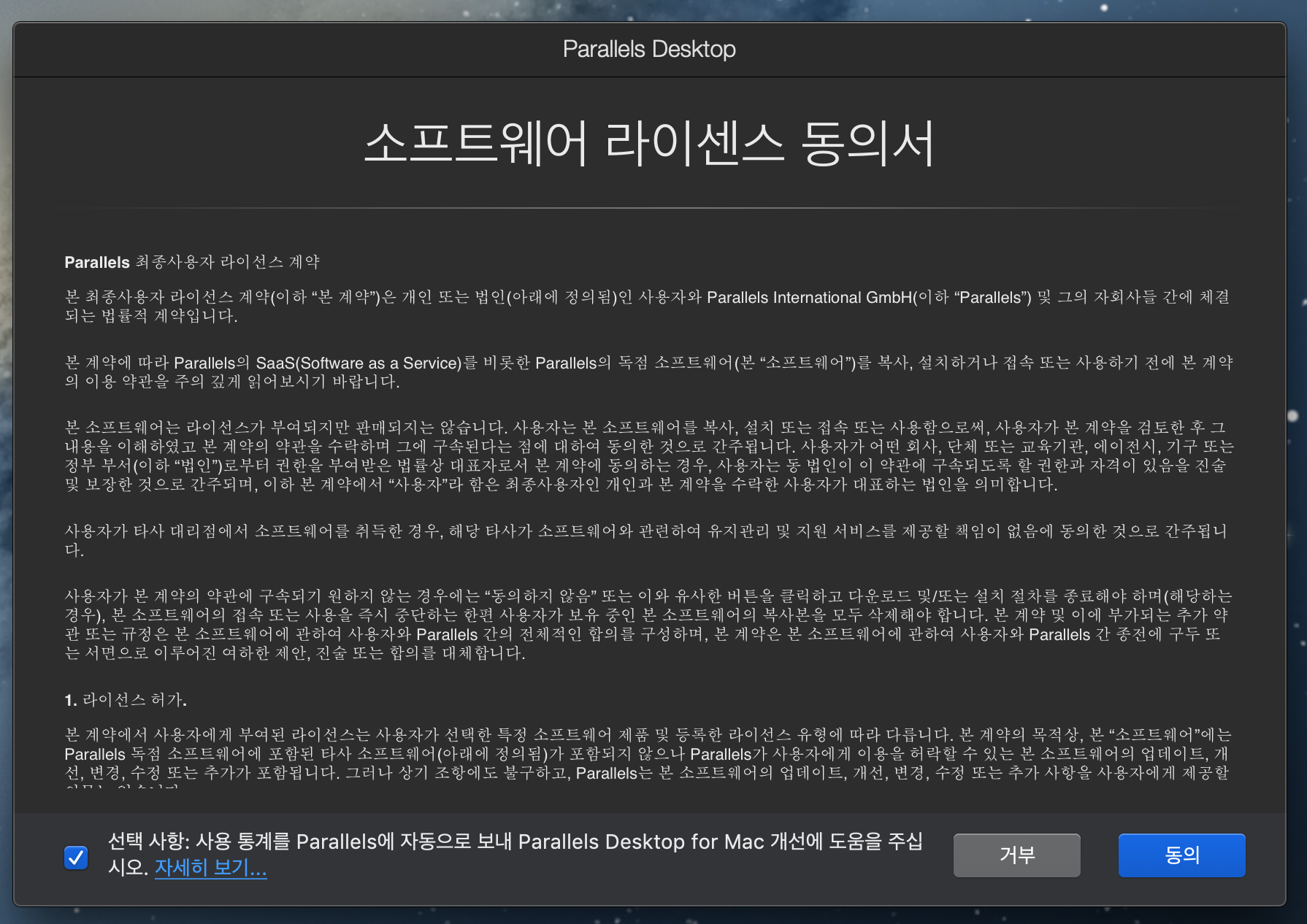
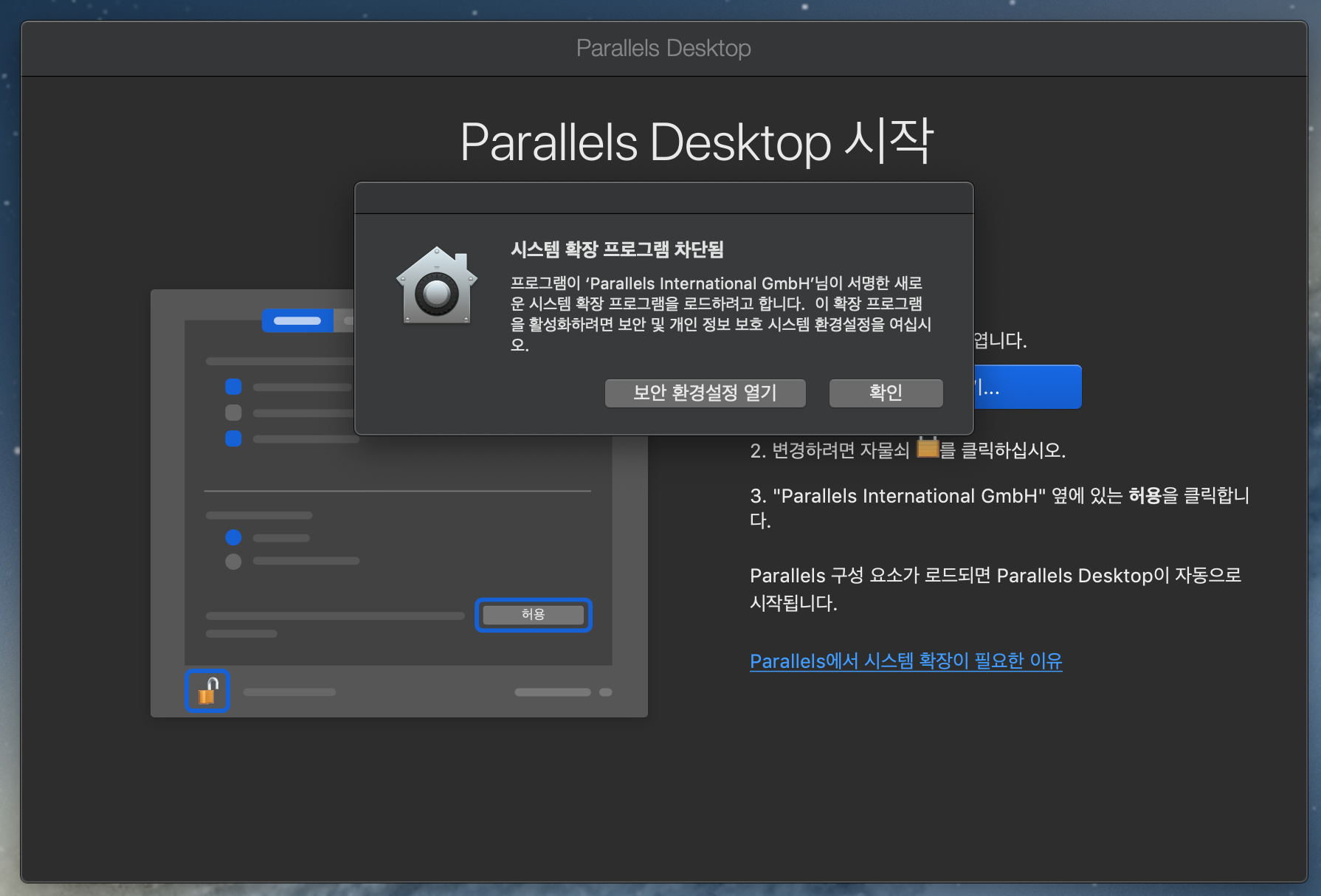
설치 방법은 너무 간단하다. 몇번의 동의, 확인, 허용만 누르면 된다.

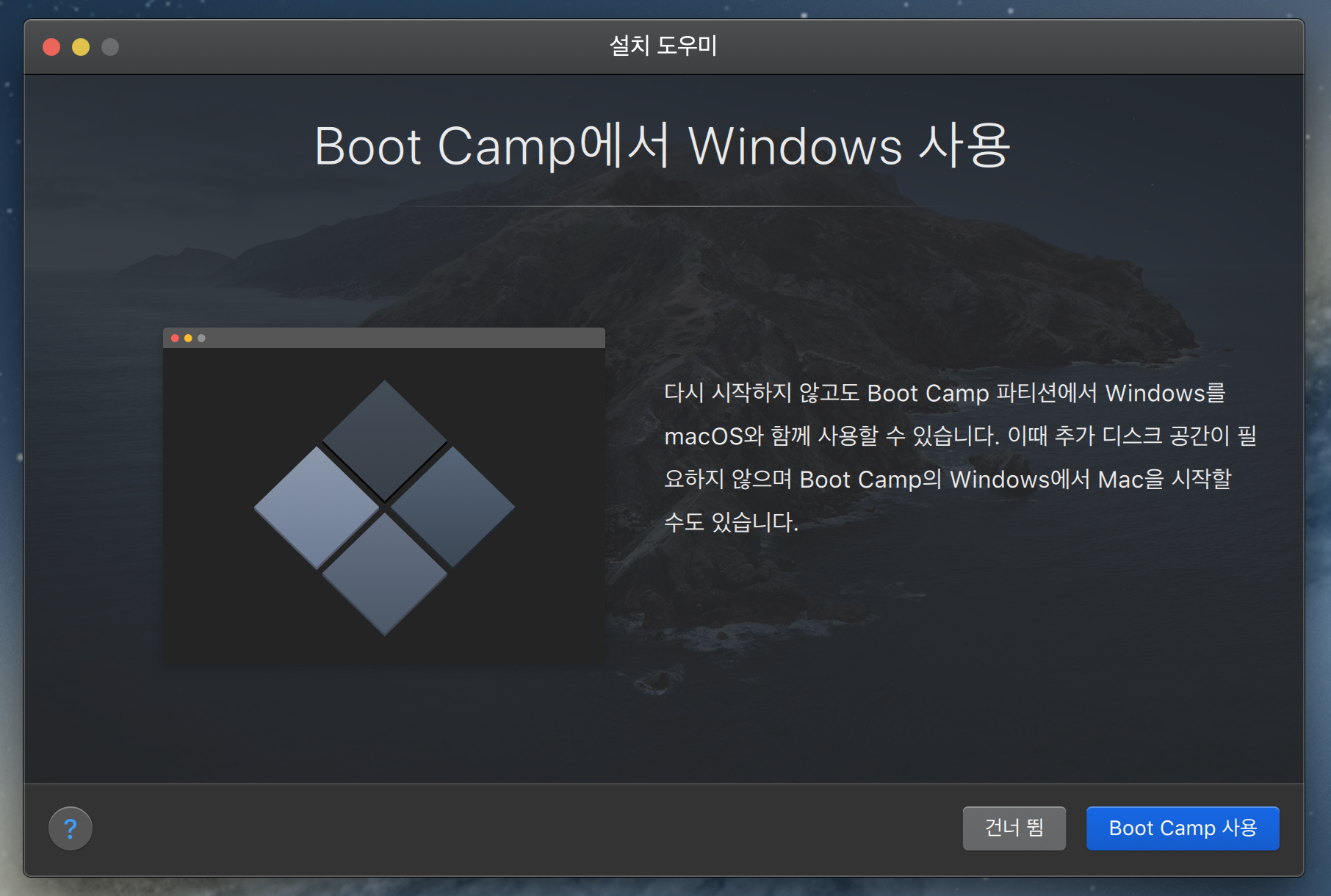
설치가 끝나면 부트캠프 있는줄 어떻게 알고, 바로 이 화면이 나온다.
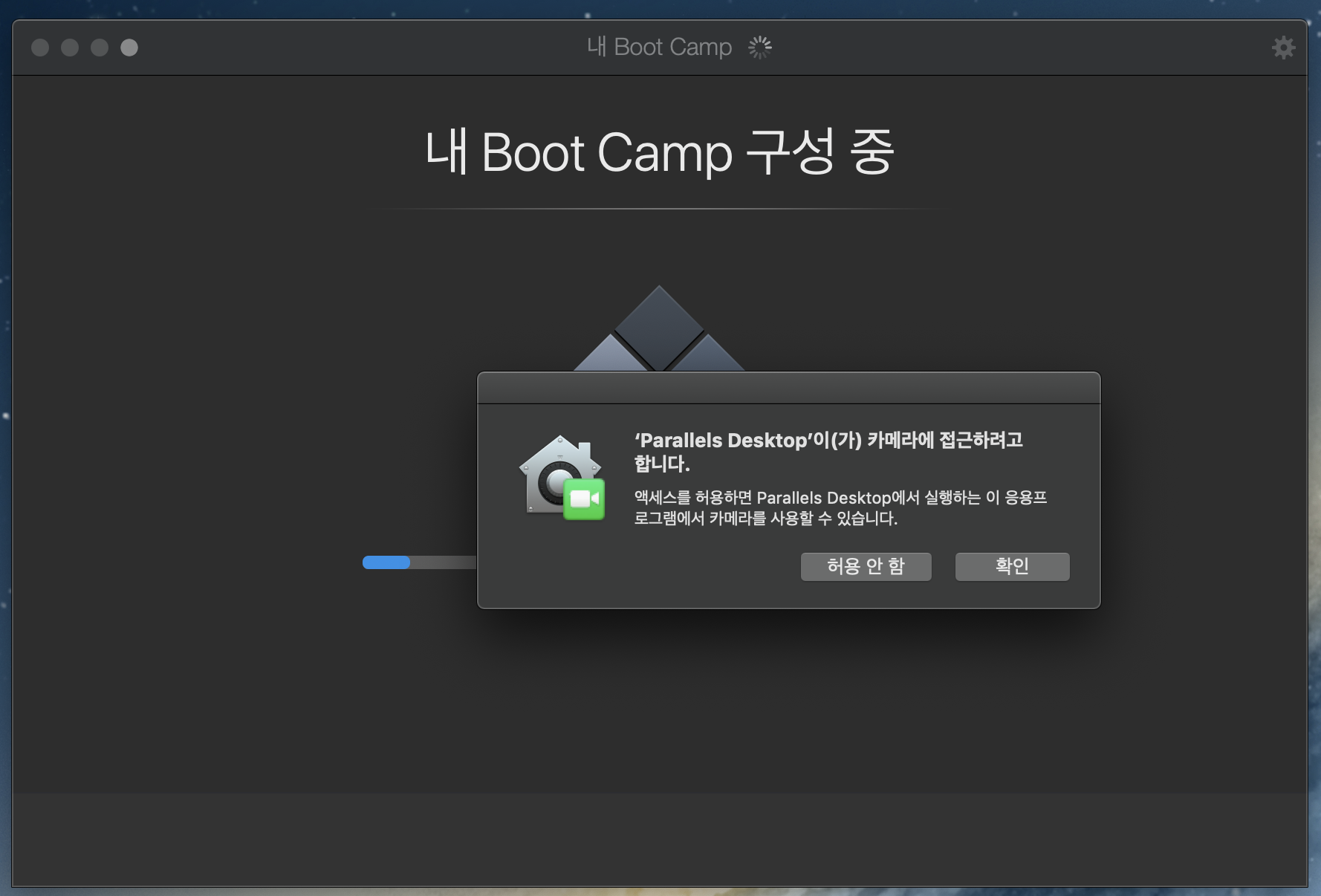
이것 또한 몇가지 확인만 하면, 완료된다.
전체화면으로 창을 확대하면,
맥과 윈도우가 왔다리 갔다리 한다.
다음엔, iMac의 부트캠프를 맥북에서 불러오도록 한다.
패러렐즈 - 부트캠프 백업 및 다른 맥에서 부르기Visual studio 2019 셋팅에서 이미 인코딩에 대해 다룬 내용이다.
요즘 게임 개발하는데, utf-8이 인코딩이 공통으로 사용되고 있어서 별로 깊게 다룰일이 없다.
개발 노트를 뒤지다가 발견했다. 피쳐폰 개발할 적이었던거 같은데, 워낙에 옛날 것이라서...
기억이 가물가물.. 자료들 출처도 정확히 모르겠고, 그래도 이런 내용이 요즘은 잘 없으니,
상식에 좋겠다는 판단하에 공유하니 한번 읽어보길 바란다.
문자열을 다루는 작업 중에서 가장 불편하고 시간 소모가 많이 드는 일이, 적절한 한글 코드 변환이다. 한글 코드는 표준으로 정해진 하나의 코드만 사용되는 것이 아니라, 여러 코드들이 각기 사용되기 때문에 데이터 입출력에 한 코드에서 다른 코드로의 변환 작업은 아주 빈번히 일어난다. 이 글에서는 한글 코드 각각에 대해서 설명하는데, 그 순서는 개발된 시간 순이다.
1. 조합형 한글 코드
맨처음 컴퓨터가 한국에 보편적으로 도입되던 시기(순전히 주관적인 판단)에 조합형 코드라는 한글 코드가 개발되었다. 조합형 코드는 다음과 같다.
맨처음 컴퓨터가 한국에 보편적으로 도입되던 시기(순전히 주관적인 판단)에 조합형 코드라는 한글 코드가 개발되었다. 조합형 코드는 다음과 같다.
| Bit Code | 10진 코드 | 16진 코드 | 초성 | 중성 | 종성 |
| 00000 | 0 | 0x00 | |||
| 00001 | 1 | 0x01 | 채움 | 채움 | |
| 00010 | 2 | 0x02 | ㄱ | 채움 | ㄱ |
| 00011 | 3 | 0x03 | ㄲ | ㅏ | ㄲ |
| 00100 | 4 | 0x04 | ㄴ | ㅐ | ㄳ |
| 00101 | 5 | 0x05 | ㄷ | ㅑ | ㄴ |
| 00110 | 6 | 0x06 | ㄸ | ㅒ | ㄵ |
| 00111 | 7 | 0x07 | ㄹ | ㅓ | ㄶ |
| 01000 | 8 | 0x08 | ㅁ | ㄷ | |
| 01001 | 9 | 0x09 | ㅂ | ㄹ | |
| 01010 | 10 | 0x0A | ㅃ | ㅔ | ㄺ |
| 01011 | 11 | 0x0B | ㅅ | ㅕ | ㄻ |
| 01100 | 12 | 0x0C | ㅆ | ㅖ | ㄼ |
| 01101 | 13 | 0x0D | ㅇ | ㅗ | ㄽ |
| 01110 | 14 | 0x0E | ㅈ | ㅘ | ㄾ |
| 01111 | 15 | 0x0F | ㅉ | ㅙ | ㄿ |
| 10000 | 16 | 0x10 | ㅊ | ㅀ | |
| 10001 | 17 | 0x11 | ㅋ | ㅁ | |
| 10010 | 18 | 0x12 | ㅌ | ㅚ |
| 10011 | 19 | 0x13 | ㅍ | ㅛ | ㅂ |
| 10100 | 20 | 0x14 | ㅎ | ㅜ | ㅄ |
| 10101 | 21 | 0x15 | ㅝ | ㅅ | |
| 10110 | 22 | 0x16 | ㅞ | ㅆ | |
| 10111 | 23 | 0x17 | ㅟ | ㅇ | |
| 11000 | 24 | 0x18 | ㅈ | ||
| 11001 | 25 | 0x19 | ㅊ | ||
| 11010 | 26 | 0x1A | ㅠ | ㅋ | |
| 11011 | 27 | 0x1B | ㅡ | ㅌ | |
| 11100 | 28 | 0x1C | ㅢ | ㅍ | |
| 11101 | 29 | 0x1D | l | ㅎ | |
| 11110 | 30 | 0x1E | |||
| 11111 | 31 | 0x1F |
이 코드는 각각의 음소를 결합해 한 글자를 만드는 방식 그대로를 이용한 것으로 초성, 중성, 종성 결합으로 만들 수 있는 모든 문자에 대해 표현 가능하다. 보다 초기에 이런 조합형 방식의 코드로 N byte, 3 byte 방식들이 존재했었다. 그 후 보다 개선된 방식으로 2Byte안에 모두 표현할 수 있는 코드가 바로 위 테이블의 코드이다.
다음 표는 2byte로 표현되어지는 한 글자가 조합형에서 실제 어떻게 구성되는 지를 표현한다.
| 1bit | 5bit | 5bit | 5bit |
| 0=영어, 1=한글 | 초성 | 중성 | 종성 |
그렇다면 위 Table을 통해 '짱'을 나타내는 2byte를 만들 수 있을것이다.
| 1bit | 5bit | 5bit | 5bit |
| 1 | 01111 | 00011 | 10111 |
즉, 1011110001110111이라는 2byte bit streams이 짱을 표현하게 되는 것이다.
2. euc-kr(완성형 한글 코드)
위 조합형 코드는 실제 OS에서 쓰이지는 않는다. 그 이유가 무엇일까?
확실한 이유는 아니지만, 추측해 보면 영문자를 표현하는 아스키와 비교해서 한글의 코드셋도 각 글자에 대해서 Table을 만들어 표현하는 것이 일관성이 있어 보였기 때문이 아닐까 한다. 즉, '가', '나', '다' 와 같은 한글에 대해서 0x11, 0x12, 0x13처럼 고정된 값을 매핑하면 아스키 코드로 a-z, A-Z를 표현하는 방식과 유사해진다.
하지만 한글에서 쓰일 수 있는 글자수는 알파벳보다 훨씬 훨씬 많다. 맨 위 표에서 볼 수 있듯이 한글은 초성개수 19개 중성개수 21개 종성개수 27개인데, 종성이 없는 경우까지 감안하면 표현 가능한 글자는 19*21*28=11172개나 된다. 아스키 코드는 겨우 256개의 data 공간을 가지는데, 한글을 여기에 다 넣기는 어림 반푼어치 없다. 그래서 한글과 같이 데이터 공간을 많이 필요로 하는 비영어권 언어를 표현하기 위해 확장 아스키 코드가 사용된다.(이 부분은 아스키 코드 관련 글을 참조) 이런 확장 아스키 코드를 이용해 한글을 표현한 코드가 흔히 알고 있는 KS 완성형 한글 코드이다. 이것은 euc-kr로도 불려지고, KSC5601이라고도 한다. 이 코드셋에는 11172개의 모든 글자를 다 코드화 하진 않았다. 자주 쓰이는 2350개의 한글에 대해서만 정의가 되어 있다.
"이 코드는 bit stream으로 어떤 모습일까요?" 라는 문자열을 KS 완성형 한글 코드로 바꾼다면 어떤 모습일까? 이 글자를 조합형으로 표현하는 것은 어렵지 않지만, KS 완성형 한글 코드로 바꾸는 것은 대단히 어렵다. 위 문자열을 KS 완성형 한글 코드로 바꾸기 위해서는 각각의 글자에 대해서 KS 완성형 한글 코드표를 보고 변환해야 하는데, 이 코드표에는 각 글자간의 어떠한 규칙도 없기 때문이다. 이 완성형 한글 코드나 확장형 한글 코드에서도 한글은 2byte로 표현된다.(잘 모른다면 ASCII Code를 설명한 글로 되돌아가 자세히 살펴볼 필요가 있다.) 한글자를 표현하기 위해서 앞 1byte는 확장형 ASCII CODE TABLE에 따라서, 그리고 그 뒤 1byte는 앞 1byte값에 따른 확장 코드 영역에 따라 정의 된다.
위 내용을 간단히 정리하면 euc-kr은 다음과 같이 구성되어 있다고 볼 수 있다.
| 상위 1BYTE | 하위1BYTE |
| 176-200(0xB0-0xC8) | 161-254(0xA1-0xFE) |
3. cp949(확장형 완성형 한글 코드)
그렇다면, 2350개의 글자에 속하지 않은 글자를 키보드로 적어 넣으면 어떻게 될까? 이 코드셋을 사용하는 어플리케이션에서는 당연히 깨져서 나온다. 초창기 인터넷 사용자라면 채팅할 때 오타 '끾'과 같은 글자는 깨져서 보여지던 것을 기억할 수 있을 것이다. 현재 인터넷에는 여러 단어의 축약형, 파생형들이 사용되는데 '햏'과 같은 것도 일종의 그런 종류이다. 이런 종류의 글자가 많아지면서 2350개의 글자로는 사용자의 요구를 충족시킬 수 없기 때문에 확장형 완성형 한글 코드가 만들어지게 되었다. 이것이 바로 CP949인데, 따라서 euc-kr은 cp949의 서브셋이라고 말할 수 있다. 그러나 cp949는 사실 ASCII Code의 원칙을 위배한 것인데, 그 이유는 ASCII Code에서 언어를 표현한 공간으로 쓰일 수 없는 영역에까지 언어 기술을 위해 사용하기 때문이다.(국제 표준 협회는 ASCII CODE에서 0-31의 제어 문자 영역과 128-159의 영역은 문자 코드로 사용하지 못하게 하였다. 그러나 CP949는 128-159 영역에 문자를 사용한다. KS 완성형 한글 코드는 이 영역을 제외한 176-200(0xB0-0xC8)까지의 공간을 사용한다.)
4. 유니코드
새로운 유니코드는 기존 코드 체계의 문제를 극복하기 위해 제안되었다. 기존 코드 체계는 어떤 문제가 있었을까?
기존 코드 체계라면 쉽게 생각할 수 있는 cp949를 예를 들어 설명해보자. cp949가 확장형 아스키 코드를 활용해 한글의 코드 셋을 표현한 것이라는 것을 상기해본다면 중국어와 일본어도 유사한 방식으로 표현되는 것을 알 수 있다.(ASCII Code를 설명한 글에서 자세히 설명) 그렇다면 독일어나 프랑스어 스페인어는 어떻게 표현되어 있을까? 우리가 본 ASCII Code 영역에는 위 다른 언어들에 대한 언급을 볼 수 없다. 그 이유는 아시아권 언어만을 고려해서 만들어진 코드 셋이기 때문이다. 그러면 독일어나 프랑스어와 같은 비아시아권 언어들은 따로 독자 코드셋을 가지고 있어야 하는데, 이런 여러 코드셋은 각 언어간의 호환을 보장하지 못하거나 어렵게 만드는 원인이 된다. 이런 문제를 해결하기 위해 유니코드가 제안되었다.
즉, 유니코드는 전세계의 모든 언어의 문자들에 대해서 호환성을 고려한 일관된 표현을 하도록 제안된 것이다. 유니코드는 2byte 문자체계라고 생각하기 쉬운데, 틀린 말이다. 유니코드는 여러가지 인코딩 방식을 가지고 있다.(UTF8, UTF16, UTF16-BE, UTF16-LE, UCS2, UCS4 등등) 이 중에서 2byte 문자체계의 인코딩 방식은 UCS2와 UTF16이다. 이런 다양한 인코딩 방식이 존재하는 이유는 표현의 제약성 때문이다. 2byte 문자체계로 세계 모든 언어를 다 표현할 수 없기 때문이다.(여기에는 모든 기호들, 고어들 포함된다.) 그래서 더 많은 메모리 공간이 필요하였고, UCS4와 같은 4byte 문자체계 인코딩 방식이 생겨난다. 그러나 고정길이 4byte 방식은 모든 언어를 다 표현할 만큼 큰 공간을 가지고 있으며 고정된 길이이기 때문에 편리한 디코딩을 지원하지만, redudancy가 너무나 큰 비효율적 문자 체계라고 할 수 있다. 그래서 모든 언어를 표현할 수 있으면서 최대한 효율적인 code를 만들려고 노력했는데, 그 결과가 UTF-8이다.
가변길이 인코딩 방식인 UTF-8은 효율성이 아주 좋지만, 언제나 그렇듯 디코딩에서는 고정길이 방식에 비해 더 많은 수고를 해야 한다.
유니코드에는 여러 인코딩 방식이 있기 때문에 각각의 인코딩 방식에 맞게 디코딩을 해줘야만 제대로 문자열을 읽어올 수 있다. 유니코드의 맵은 너무 커서 제대로 살펴보기 어렵지만 개략적인 정리는 다음과 같다.

기본 2byte영역에 들어가는 부분이 기본 다국어 평면 영역이다.(이 코드 영역은 Window운영체제에서는 보조프로그램의 시스템도구의 문자표에서 확인할 수 있다) 이외 보조 다국어 평면이나 보조 상형 문자 평면이나 보조 특수 목적 평면과 같은 데이터 영역은 기본 다국어 평면에 다 담을 수 없는 기타 글자들을 위한 공간이다. 이 코드표를 활용해 문자를 표현하면 된다. 한글 영역과 기본적인 한자는 기본 다국어 평면에 다 들어가 있다. 보다 자세한 내용은 위키피디아나 유니코드 홈페이지에서 볼 수 있는데, 일반적으로 사용하는 경우 기본 다국어 평면 만을 대상으로 작업한다고 생각해도 무리가 없다.(없길 바라는게 정신 건강에 좋을 수도... 어려운건 아니지만 복잡한건 누구나 싫어하니까...)
글이 길어져서 급 마무리 하려고 하니, 여타의 필요 없는 부분은 모두 생략하고 필요한 부분만 언급한다. 아스키 코드 영역은 0x0000-0x00FF에 기술되어 있다. 한글이 정의되어 있는 영역은 다음 그림을 보면 쉽게 알수 있다.
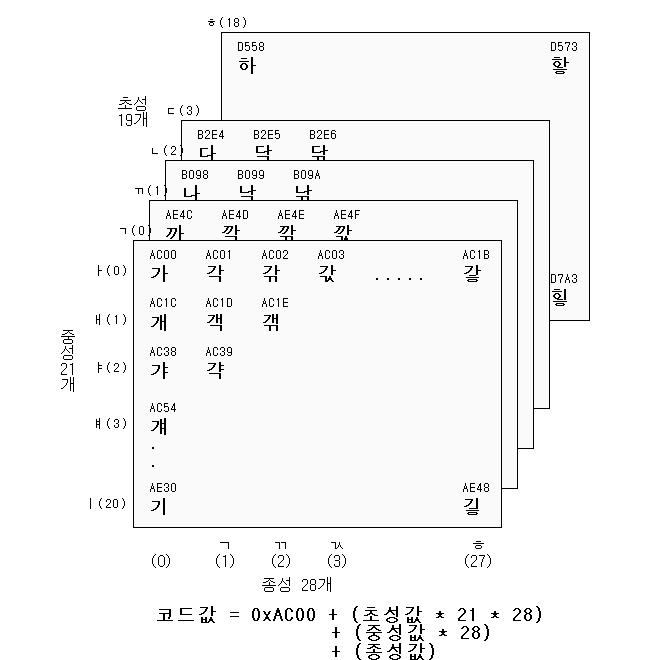
위 그림을 보면 알 수 있듯이 한글은 다음 식에 의해 계산될 수 있다.
한글 코드값 = 0xAC00 + (초성값*21*28) + (중성값*28) + 종성값
초성, 중성, 종성의 개수가 각각 19개, 21개, 27개(종성이 없는 경우 포함하면 28)임을 생각하면 어떤 형태로 코드 값이 계산되는지 이해할 수 있다.
이것을 대표적인 인코딩 방식 UTF-8로 표현하려면 다음의 가변길이 코드 Map을 활용해야 한다.
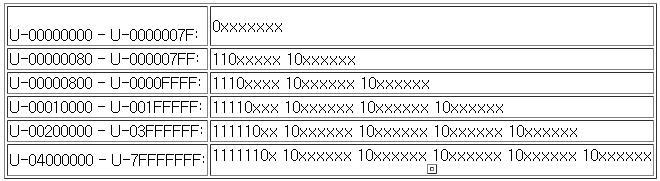
이것을 보면 왜 UTF-8이 사실 효율적인 측면을 제외하고, 코드값을 계산하는 측면이나, 자소를 분리하는 측면 모두에서 확장형 한글 완성형 코드보다 뛰어날 것을 짐작할 수 있다.
한글의 코드 체계는 대단히 복잡해 보일 수 있는데, 사실 자세히 파고 들면 그렇게 어렵지 않다. 하지만 그 막연함을 자세히 파고 들지 않으면 문자열을 다룰때마다 애를 먹게 된다. 이 기회에 자세히 이해하고 넘어간다면 문자열을 처리하는 작업이 오히려 즐거운 일이 될 수 있을 것이다.
랜덤(Random), 난수란게 순서나 규칙이 눈에 보이지 않아야 하며, 연속적인 임의의 수여야 합니다.
이전과 이후의 수열이 예측되지 않도록 독립적인 임의성을 가져야 하며,
수의 범위내에 있는 모든 수가 최대한 동일한 확률에 가까워야 하는 분포도여야 한다.
다행인건 기본적인 함수는 제공해준다.
게임에서 간단하게 쓰려면 이 정도까지만 해도 괜찮을(?)지도 모른다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
void main()
{
// 앱이 구동되면 한번만 호출.(seed 값 1번 설정)
// main이 호출 되는 시점 또한 랜덤하기 때문에,
// time(NULL)이 seed값으로 무난하게 쓰인다.
srand((unsigned)time(NULL));
// 10의 랜덤 수를 구한다.
for(int i=0; i<10; i++)
printf("rand[%d] = %d\n", i, rand());
}
|
cs |
근데 뭔가 찜찜하다..
게임 개발하면서 최소 한번 이상은 랜덤에 대해 고민하게 될것이다.
공격 크리티컬 판정, 회피율, 아이템 드랍율, 강화성공, 등등
지금 당장은 게임에 이런저런 복합적인 요소들이 들어가지 않더라도,
언젠가는 인기있는 게임자가 될테니...그때를 대비하여서라도 준비를 해두는것도 괜찮을 것이다.
함수 rand()는 int 자료형의 크기가 2바이트(=16비트)일때 만들어진 함수다.
그래서 반환되는 랜덤 생성 범위가 0 ~ 32,767 밖에 안된다.
만드는 게임에 따라 이 정도면 충분할 수도 있고, 많이 부족할수도 있다.
수학을 조금? 아는 사람이라면 분포도가 고르지 못하다는것도 대충 어림짐작 할 것이다.
그럼 직접 간단히 만든다면, 대충 이와 비슷하지 않을까?
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
|
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
unsigned int seed;
void SRAND(unsigned int s = 5323)
{
seed = s;
}
unsigned RAND()
{
seed = 8253729 * seed + 2396403;
return seed % 32768;
}
void main()
{
SRAND();
for(int i=0; i<10; i++)
printf("rand[%d] = %d\n", i, RAND());
}
|
cs |
근데 이건 pseudo-random number generator(PRNG)란 거다.
일단 아이디어가 떠오르면 만들려고 하지 말고, 검색부터 해보자.
왠만한건 사람들이 다 만들어 놓았다.
링크를 타고 가면 4개가 보일것인데, 어느것을 사용하더라도
더 나은 결과물을 얻게 된다. 링크 타고 가보면 딱히 어려운 부분도 없어서 그대로 쓰기에도 딱 좋다.
쉐이더 프로그래밍하는곳에서도 다양하게 만든 랜덤함수들을 보게 될것이다.
시간을 이용하기도 하고, perlin noise같은 여러 노이즈를 활용하는 등의 다양한 랜덤을 볼수 있다.
이 부분은 지문이 너무 길어져서..;;
공식 사이트 Shadertoy
페이스북에 국내 모임도 있으니 참고하면 좋을것이다.
다시, 자작용 함수를 고민해보자.
rand()함수의 한계를 극복하고, 램덤 생성 수의 범위를 넓혀 4바이트짜리로 만들어 보는 것이다.
|
1
2
3
4
5
6
7
|
unsigned int RAND()
{
int hi = rand();
int lo = rand() + rand();
return (hi << 16) + lo;
}
|
cs |
이 함수는 4바이트의 램덤수가 생성되지만, 균일한 분포가 확률적이지가 않다.
4바이트는 16진수로 표시하면 0x00000000 ~ 0xFFFFFFFF 이렇고, 8자리다.
각 자리 0x0 ~ 0xF 랜덤하게 생성하고 밀어붙이는 것이다.
|
1
2
3
4
5
6
7
8
9
10
11
|
unsigned int RAND()
{
unsigned int n = 0;
for(int i=0; i<8; i++)
{
n <<= 4;
n |= rand() % 0x10; // 0x0 ~ 0xF 나오도록 0x10으로 나머지 연산
}
return n;
}
|
cs |
대충 괜찮은 함수 같다. 8바이트 짜리를 생성한다면 for에서 16번을 호출하고 타입만 바꾸면 된다.
반복문을 줄이고 싶으면, 각 자리 0x00 ~ 0xFF 랜덤하게 생성하고 밀어 붙이는 것이다.
|
1
2
3
4
5
6
7
8
9
10
11
|
unsigned int RAND()
{
unsigned int = n = 0;
for(int i=0; i<4; i++)
{
n <<= 8;
n |= rand() % 0x100;// 0x00~0xFF 나오도록 0x100으로 나머지연산
}
return n;
}
|
cs |
랜덤에는 정답이 없지만 그렇다고 딱히 어려운것은 없다.
다만, 본인이 만들고 있는 게임에 적당한 랜덤 함수를 찾아내는것이 어렵다.
|
1
2
3
|
#define randomM1to1 ( (rand() / (float)0x3fff) - 1.0f )
#define random0to1 ( rand() / (float)0x7fff )
|
cs |
그럼 매크로만 남기고 글을 마친다.
필요한 셋팅을 하나씩 포스트할 예정이다.
이번에는 말도 많고 탈도 많은 언어 인코딩에 대해서 작성한다.
프로그램을 구동시킨다.

여기는 임시로 DRVN이라는 솔루션을 만들었고, 원하는 이름으로 하나 만들면 되겠다.
그럼 해당 솔루션 폴더에 가서, .editorconfig 파일을 만든다.
파일을 열어서 작성한다. 이 화면은 visual code에서 작성한 장면이다.
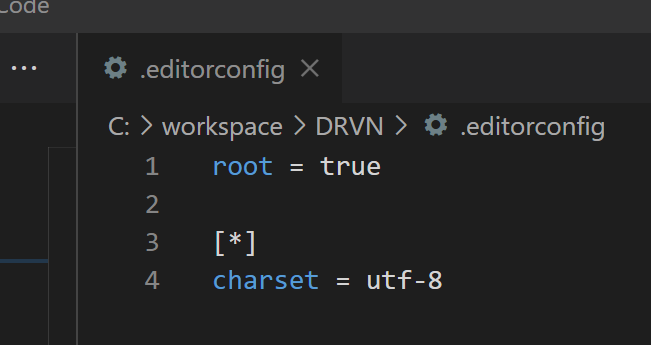
오타가 날수도 있으니, 코드도 같이 올린다.
1 2 3 4 5 | root = true [*] charset = utf-8 | cs |
프로젝트명 우클릭 후 속성으로 들어간다.

C/C++ > 명령줄 > 추가 옵션에 /utf-8 입력후 확인
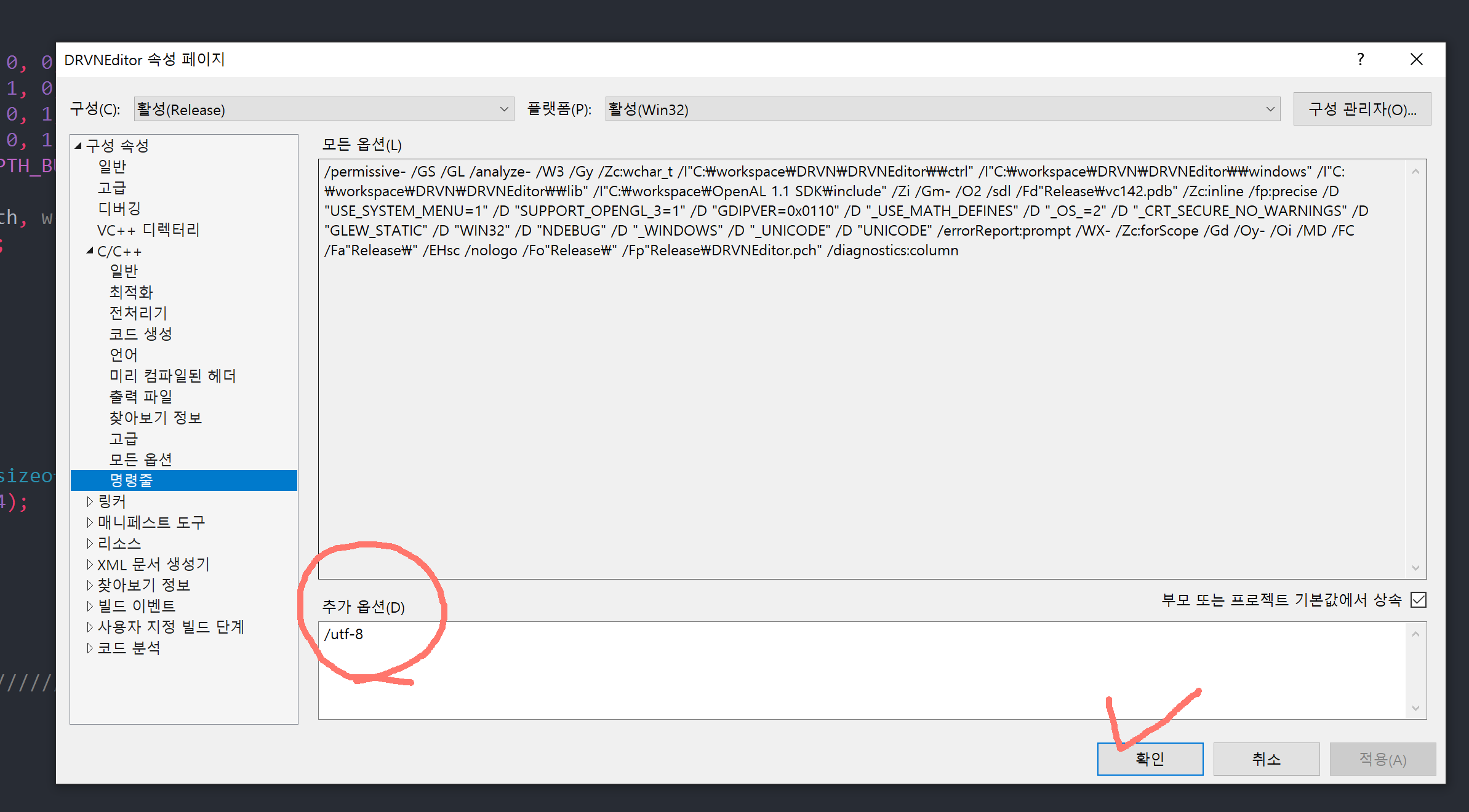
이제 코드를 작성하고 저장하거나 빌드를 하게 되면 무조건 utf-8로 모두 저장이 된다.
왜? utf-8로 작성해야 하는지 다음에 작성하겠다.
연속 vs 불연속 1 이어 작성한다.
지난 포스터에서 말했듯이, 컴파일 에러를 막더라도 런타임 에러는 막을수 없다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
void main()
{
int i, j;
//int a[4][2] = { {0, 1}, {2, 3}, {4, 5}, {6, 7} };
//동적 할당으로 위의 값처럼 대입
int** a = (int**)malloc(sizeof(int*)*4);
for(i=0; i<4; i++)
{
a[i] = (int*)malloc(sizeof(int)*2);
for(j=0; j<2; j++)
a[i][j] = 2 * i + j;
}
int* b = (int*)a;
for(i=0; i<8; i++)
printf("b[%d] = %d\n", i, b[i]);
}
|
cs |
a는 결국 연속적이지 못하기 때문에, 아래처럼 쓸수 밖에 없다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
void main()
{
int i, j;
//int a[4][2] = { {0, 1}, {2, 3}, {4, 5}, {6, 7} };
//동적 할당으로 위의 값처럼 대입
int** a = (int**)malloc(sizeof(int*)*4);
for(i=0; i<4; i++)
{
a[i] = (int*)malloc(sizeof(int)*2);
for(j=0; j<2; j++)
a[i][j] = 2 * i + j;
}
int** b = a;
for(i=0; i<4; i++)
{
for(j=0; j<2; j++)
printf("b[%d][%d] = %d\n", i, j, b[i][j]);
}
}
|
cs |
다만, b[0], b[1], b[2], b[3]가 가지고 있는 메모리는 연속적이라서 아래처럼 쓸수 있다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
void main()
{
int i, j;
//int a[4][2] = { {0, 1}, {2, 3}, {4, 5}, {6, 7} };
//동적 할당으로 위의 값처럼 대입
int** a = (int**)malloc(sizeof(int*)*4);
for(i=0; i<4; i++)
{
a[i] = (int*)malloc(sizeof(int)*2);
for(j=0; j<2; j++)
a[i][j] = 2 * i + j;
}
int** b = a;
for(i=0; i<4; i++)
{
int* c = b[i];
for(j=0; j<2; j++)
printf("b[%d][%d] = %d\n", i, j, c[j]);
}
}
|
cs |
공부하는 입장에서 보면 이 예제가 별로 도움이 안될것 처럼 보일것이다.
조금 윽지 스럽지만, 게임 상에서 활용될때 이런식으로 표현된다.
유형 1, 유형 2 실행하면 동일한 효과가 나온다.
메모리의 연속과 불연속을 제대로 이해하고 있을때 코드의 표현력이 달라진다.
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
|
struct Monster
{
const char* name;
int hp;// 체력
int ap;// 공격력
int dp;// 방어력
float rate;// 공격속도
};
Monster monster[2][4] =
{
// 지상 유닛
{
{ "쥐", 10, 3, 2, 0.1f },
{ "토끼", 10, 3, 2, 0.1f },
{ "고양이", 10, 3, 2, 0.1f },
{ "개", 10, 3, 2, 0.1f },
},
// 공중 유닛
{
{ "참새", 10, 3, 2, 0.1f },
{ "비둘기", 10, 3, 2, 0.1f },
{ "까마귀", 10, 3, 2, 0.1f },
{ "독수리", 10, 3, 2, 0.1f },
}
};
void main()
{
int i, j;
const char* str[2] = { "지상 유닛", "공중 유닛" };
// 유형 1
for(i=0; i<2; i++)
{
printf("<<< %s >>> \n", str[i]);
Monster* mon = monster[i];
for(j=0; j<4; j++)
{
Monster* m = mon[j];
printf("Monster[%d][%d] = { %s, %d, %d, %d, %f}\n",
i, j, m->name, m->hp, m->ap, m->dp, m->rate);
}
}
// 유형 2
for(i=0; i<8; i++)
{
if( i%4 == 0 )
printf("<<< %s >>> \n", str[i/4]);
Monster* m = monster[i][j];
printf("Monster[%d][%d] = { %s, %d, %d, %d, %f}\n",
i, j, m->name, m->hp, m->ap, m->dp, m->rate);
}
}
|
cs |